什麼是AI爬蟲 (AI Crawler)
首先要理解現在像ChatGPT這些AI,它們的常識來源有一大部份是透過網站內容取得,透過AI爬虫不斷從網路抓取資料來訓練AI。其實它們做的事情跟搜尋器爬虫是差不多,差異在於AI競賽當中,AI公司需要在短時間內取得更多資料,所以會採取更進取的方法爬蟲。
為什麼AI爬虫會造成震撼賬單?
「更進取」的意思是,AI爬蟲會用更密集,更高頻率方式去拿資料,這個會對網站主機造成額外的負擔。
我們曾經處理過最極端的案例是,網站放在某大雲端,Instance CPU長期100%,網站等於直接掛掉。我們協助把網站搬遷過來進行過濾,看到網站有超過 95%流量都是來自單一AI爬虫(某社交媒體的AI爬虫)。這裡看到兩個問題,首先以上個案反應AI爬蟲已經影響網站穩定性本身,同時客戶因為這樣花了一筆額外的費用而造成震撼賬單,因為雲端是按算力計算收費的,而這個過案,絕大部份算力都是被那個爬虫佔用,而不是一般訪客。
下方截圖是另一位客戶的記錄,可以看到排名第一的爬虫佔超過三份一流量,是排名第四爬虫的二十倍 。留意截圖顯示的 34.69%抓取的都是動態內容,所以實際資源佔用影響遠遠高於三份一。

什麼網站會特別受爬虫影響?
根據我們經驗,多內容,多頁數的網站會比較受AI爬虫影響,例如論壇,部落格,購物網站等等。而其中最近我們發現爬虫有嘗試針對分類頁面較多,或者有過濾功能的頁面進行更進取的爬蟲行為。這些功能比較吃主機資源,同樣造成額外負擔。
現在過濾AI爬虫的辦法,這些辦法真的有用嗎?
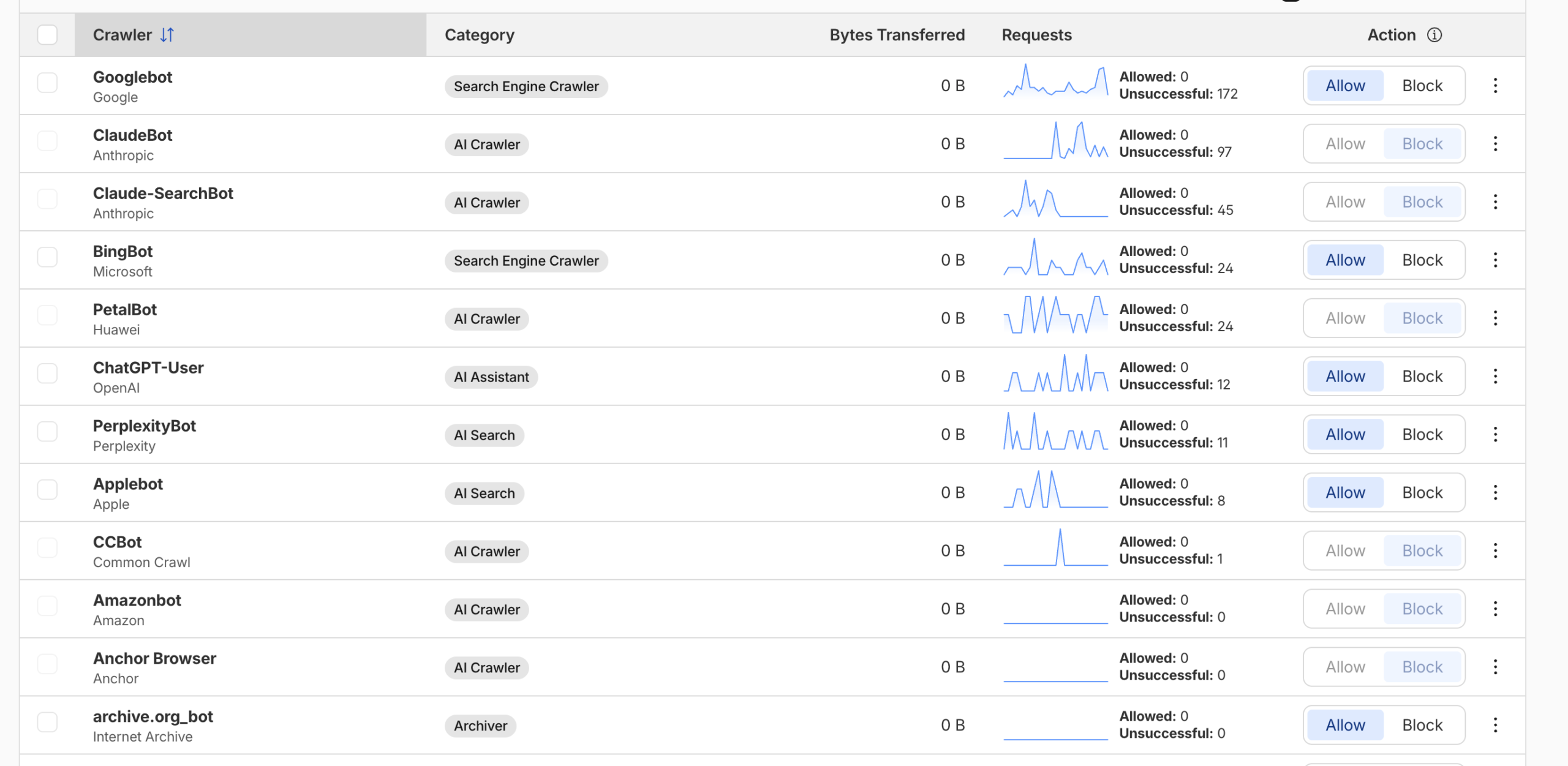
比較知名,而又有提供免費過濾功能的應該是Cloudflare,他們可以讓用家選擇封鎖特定甚至完全封鎖AI爬虫。這裡有兩個問題
1、封鎖某社交媒體的爬虫,有可能會影響網站連結分享到某社交媒體 (缺少了預覽)。
2、能夠封鎖的前提是AI爬虫說自己是爬虫,但現在很多爬虫並沒有這樣做,所以單純以Useragent過濾並不是100%有效方式。
過濾會有什麼壞處?
有些客戶會使用「操SEO」的概念去「操AI」,例如灌輸那個那個網站的產品特別好給AI,假如網站封鎖了AI,那效果可能會未如理想。
你們有什麼處理方式?
早於Cloudflare 有提供AI Bot過濾功能之前,其實我們已經有注意到AI爬虫的潛在問題,而我們立場是
1、沒有表明,但行為是AI爬虫,而且來源可疑,我們直接封鎖
2、保持不主動干預,但假如有影響主機穩定性,我們會主動封鎖
3、我們有特別為某社交媒體的AI爬虫客製化限流方式,當客戶網站受波及的時候,我們會設置限流但網站影響可以正常於某社交媒體分享並且能夠正確顯示預覽。
假如你的網站也受AI爬虫的困擾,歡迎聯絡我們了解我們提供的虛擬主機方案。